スーパーコンピュータを活用した大規模計算の実施やお客様が社外の計算機環境の利用をできるよう、種々の計算機でチューニングを行っております。
● 稼働実績のある国内のスーパーコンピュータ(2024年 現在)
| 名称 | CPU、アーキテクチャ | 設置場所 |
| 富岳 | FUJITSU A64FX | 理化学研究所計算科学研究センター(R-CCS) |
| FOCUS スパコンシステム | Intel Xeon | 公益財団法人 計算科学振興財団 |
| 地球シミュレータ | NEC SX-ACE | 海洋研究開発機構(JAMSTEC) |
| スパコンシステム ITO | Intel Xeon | 九州大学 |
| 学際大規模計算機システム | Intel Xeon | 北海道大学 |
| SQUID | Intel Xeon | 大阪大学 |
| Wisteria/BDEC-01 | FUJITSU A64FX | 東京大学 |
| TOKI-SORA(JSS3) | FUJITSU A64FX | 宇宙航空研究開発機構(JAXA) |
● スパコンによる並列計算性能
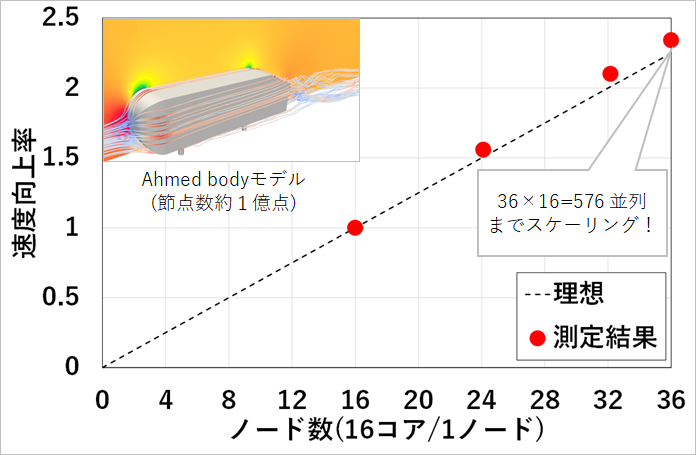
Fujitsu 製 PRIMEHPC FX10 を用いて、大規模格子に対する並列性能のテストを行いました。対象とするのは、車体周り流れ解析の標準モデルである Ahmed body モデルです。この解析では、車体周りに2回の格子細分化が行われ、節点数は約1億点となっています。並列数を変えて計算時間を測定した結果、約 600 並列までほぼ理想的にスケーリングしました。
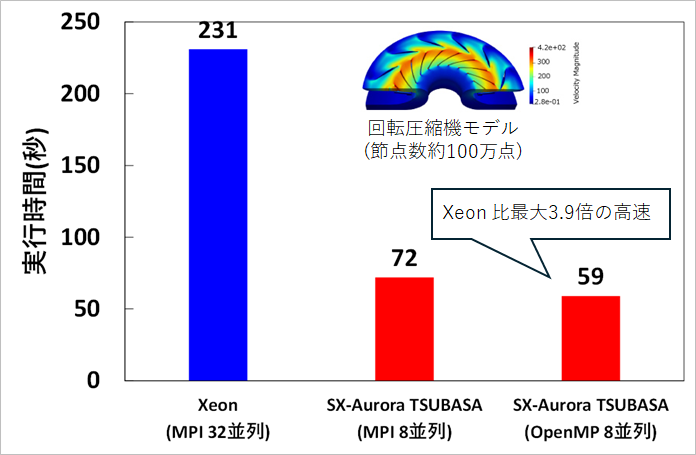
● SX-Aurora TSUBASA によるベクトル計算
圧力計算に現れる連立一次方程式の解法にマルチカラー法を導入するなど、ベクトル機向けのアルゴリズムに変更することで高速化を実現しました。
解析対象は、解析ニーズの高い回転圧縮機モデルとし、スライディングメッシュによる解析を行いました。その結果、MPI による並列で Xeon サーバと比較して約 3.2 倍の高速化、さらに OpenMP による並列化を行ったところ、約 3.9 倍の高速化が達成されました。
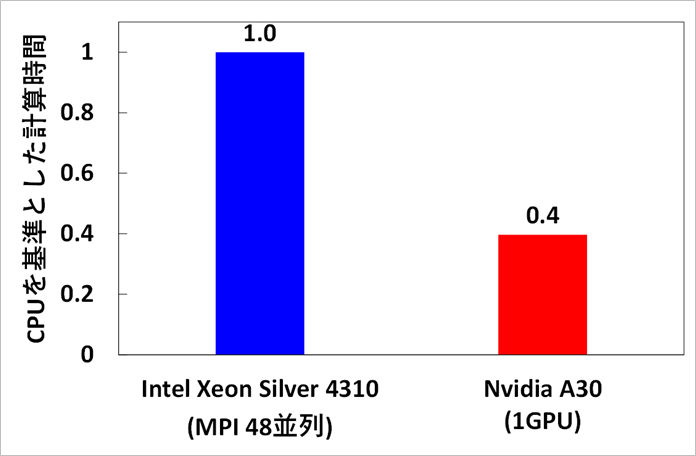
● NVIDIA GPU による高速化
現在では、Graphics Processing Unit(GPU)による解析に取り組んでいます。
ポアソン方程式を解くための ICCG 法ソルバーに、CuSparse のライブラリーを適用し、単体の GPU 上で実行可能にし、反復ループの計算時間を計測しました。その結果、非構造メッシュ約 530 万要素での計算において、1GPUでの計算により、従来の CPU による並列計算(MPI 48 並列)に対して、2.5 倍の高速化を達成しました。
今後も、化学反応など計算時間を要する部分を中心に GPU による高速化を進める予定です。